Annotator
Posted on 17 April 2020 in dev
I have a few books that I've scanned along the years and times to times, somebody shares a PDF made of images of text.
If we want to do something with the text (edit, copy/paste, and so on), either we painfully rewrite it or we can use OCR. I'm a lazy person and if I can automate something I will (that might not save me time but at least I will have fun and learn something).
That's why I made Annotator.
Annotator mascot
Annotator
Actually Annotator does more than just annotate. It can:
- manually annotate,
- automatically annotate,
- stitch annotations together,
- OCR the text,
- translate the text.
The stitching, OCR and translation are done via scripts for the moment but I'm considering adding that to the main annotation software.
Data annotation
First I need to get the text from the image. I have several options:
- annotate myself,
- automate the annotation, or
- both.
Manual annotation
Easy, right? We draw a rectangle, the annotation, with the mouse and you are done. This is what happens more or less.
I needed a GUI to display the image and something to listen to the mouse. I picked
Flask and Fabric js respectively.
Fabric js
I'm not a js person so I might have missed the perfect library for drawing rectangles on the top of an image. Nonetheless I was surprised by the lack of choices in the matter.
I have no merit here: I customized the drawing editor example from Fabric. Basically we want to display the image to annotate in a HTML5 canvas which is an element made to draw graphics in it and Fabric extends on it.
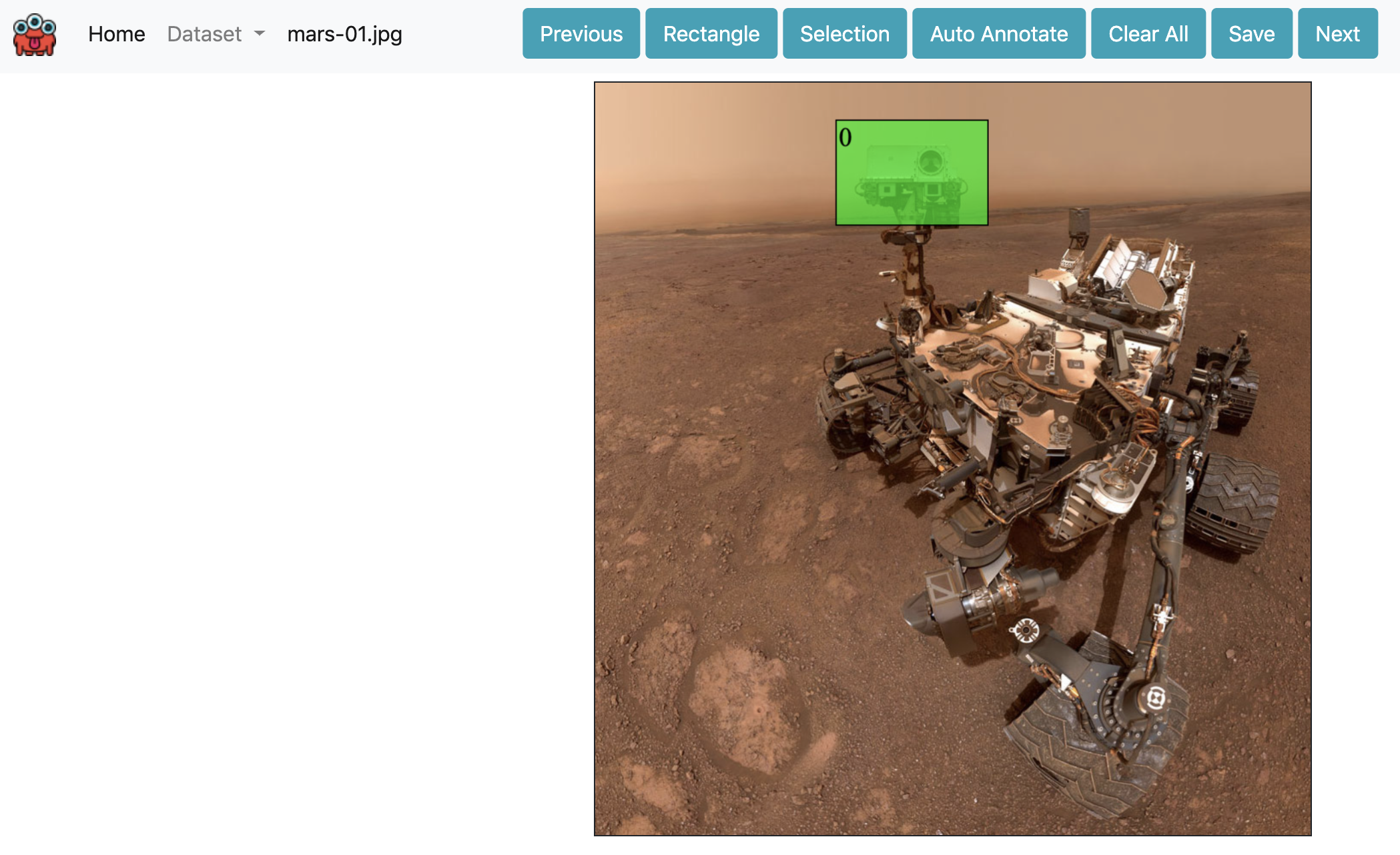
I know it's not text, it's Curiosity
I have added three main functionalities:
- each annotation gets a number,
- keyboard shortcuts and navigation,
- the image to annotate gets scaled to fit vertically in your browser.
For the last one, the images tend to have a high resolution, making it tedious to scroll down to annotate while pressing down a mouse button.
Automatic annotation
How to you automatically detect blocks of text in an image?
I used to do computer vision, mostly with opencv. Since deep learning took over, I haven't done anything in that space but I knew that somebody somewhere must have solved my problem. After looking at what has been done, I came up with a simple way to do it:
- put the image in black and white if not already,
- dilate it,
- find the contours,
- draw them.
Done! You might want to add some filters here and there like a blur but that's not necessary.




Regular image, threshold, dilatation, box
Data extraction
Once we know where the text is, we need to recognize what each character is. To do so, I propose two options:
- local OCR system like
tesseract, - a cloud-based service like
Google vision
When I shared the draft of this post, friends asked me about deep learning models.
I looked into one included in the last opencv version (v4 now).
T. shared with me CRAFT, a paper by NAVER labs.
- EAST: An Efficient and Accurate Scene Text Detector by Zhou et al.,
- CRAFT: Character-Region Awareness For Text detection by NAVER
I haven't compared the different systems for the moment but I think it would be a great follow-up article.
Issues
If you let the automatic annotation do the work for you will end up with random box numbers all over your annotated images. This might impact the OCR stage as OCR systems don't care about the layout; you will get text from different columns on the same line, adding extra untangling effort.
How to solve this
In one column setting, it's easy. You start with the top box and then you enumerate from left to right, top to bottom - assuming you work with a language working that way.
In a two-column setting, it's a bit more trickier. One way to look at it is to:
- create a histogram representing the sum of the boxes y-pixels along the x-pixels,
- look at the lowest points: should be left side (~0), the right side (~width) and the lowest point between 0 and width should be the separation between the columns,
- for each column, enumerate from top to bottom, left to right, starting with the column the most left.
Here you have solved most of your enumeration issue.
Conclusion
This project is useful to me as I didn't find a tool which could satisfy my needs. As much as I don't like to work with javascript code, I recognize that it does the job when you need real-time processing or action done on client side (drawing would be one of the use-cases).
The time I gain using my tool does not necessarily make up for the time I spent coding it. What is worthy to me is the decrease in tiredness and cognitive load spent on trivial tasks. This energy I would prefer spend on fun or rewarding activities.
Acknowledgments
This post was first posted as a draft, so I could get quick feedbacks from friends. I got great comments and I have incorporated them in the final version. Thank you again for the help and the nice words.